
据新书6月19日报道,据新书6月19日报道,“中国电信”中国电信人工智能研究院官方微博发文(TeleAI)北京智源人工智能研究院与北京智源人工智能研究院联合发布世界上第一个单体密度万亿参数语义模型Telele-FLM-1T已成为国内首批发布密集万亿参数大模型的机构之一。
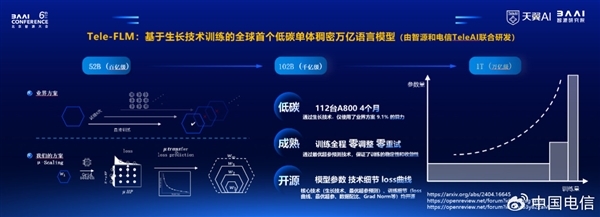
面对大型模型训练过程中计算能力消耗的巨大挑战,Tele人工智能和智能源通过深度研发,结合模型生长和损失预测等关键技术,成功推出了Tele-FLM系列模型。在计算能力资源的使用上,这一系列模型只消耗了行业普通培训计划的9%,显示出很高的计算能力效率。

使用112台A800服务器,TeleAI团队在短短4个月内完成了3个模型,总共2.3T tokens的训练,无需任何调整和重试,充分证明了模型训练的稳定性和收敛性。
值得一提的是,Tele-FLM-1T版本即将开源,旨在为社区提供技术参考,培训万亿密集模型,有效解决万亿模型训练收敛困难等问题,进一步促进大模型技术的进步。
Tele人工智能不仅在技术创新方面取得了突破,而且通过开源方式积极推动大模型技术的普及和本地化。他们接连开源7B、12B、大型52B参数模型在开源社区引起了广泛的讨论和应用。开源模型下载量超过1万次,吸引了40多万用户。
[本文结尾]如需转载,请务必注明出处:新书
负责编辑:鹿角
文章内容报告
")


还没有评论,来说两句吧...