
芯片初创公司Etched近日宣布推出一款针对芯片初创公司的Etched Transformer架构专用AISC芯片 “Sohu”,并声称自己在AI大语言模型中(LLM)推理性能击败了NVIDIA最新的B200 GPU,人工智能性能是H100的20倍。
这也意味着Sohu芯片将大大降低现有AI数据中心的采购成本和安装成本。
目前,Etched公司已直接与台积电4nm技术合作生产Sohu芯片,并从顶级供应商那里获得了足够的资金 HBM 和服务器供应,以快速提高第一年的生产能力。
一些早期客户已经向Etched公司预订了数千万美元的硬件。

AI性能超过NVIIDIAI H100的20倍是怎么做到的?
据Etched公司介绍,Sohu是世界上第一个基于Transformer架构的ASIC。
根据Etched披露的数据,配备8个Sohu芯片的服务器每秒可以处理超过8个Sohu芯片 500,000 个 Llama 70B Token,同样配备8张NVIDIA H100 GPU加速卡服务器的20倍。
同样,也远远超过了配备8个NVIDIA的最新B200 GPU加速卡的服务器约为10倍。
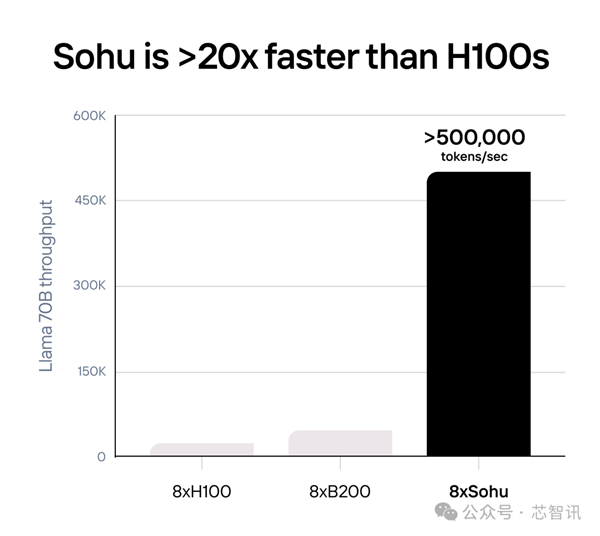
△基准测试是针对的 FP8 精度的 Llama-3 70B:无稀疏性,8x 模型并行、2048 输入/128 输出长度。使用 TensorRT-LLM 0.10.08(最新版本)计算 8xH100,8xGB200 数字是估算出来的。
Etched表示,Sohu的速度比NVIDIA最新一代Blackwelll架构的B200快 GPU的数量级更快,而且价格更便宜。它可以帮助客户建立起来。 GPU 无法实现的产品。
不过,这里还是要强调的是,虽然Sohu的AI性能比NVIDIAGPU好,但是有一个前提,因为Sohu是专门为基于Transformer架构的大模型定制的,所以它也只支持基于Transformer架构的大模型加速。
“通过将Transformer架构集成到我们的芯片中,虽然大多数传统的传统芯片都无法运行 AI 模型,如为 Instagram 广告提供支持 DLRM、像 AlphaFold 2 这种蛋白质折叠模型,如蛋白质折叠模型, Stable Diffusion 2 这样的旧图像模型,以及CNN、RNN 或 LSTM等模型,但对于基于Transformer架构的大模型来说,Sohu将是历史上最快的人工智能芯片,没有一个芯片能与之匹敌。”Etched公司说。
1、更高的计算利用率
因为Sohu只运行Transformer这种算法,所以可以删除绝大多数控制流逻辑,从而拥有更多的数学计算逻辑。因此,Sohu FLOPS 利用率超过 90%(而使用 TRT-LLM 的GPU上 FLOPS 利用率约为 30%)。
尽管NVIDIA H200 拥有 989 TFLOPS 的 FP16/BF16 计算能力(无稀疏性),这无疑是非常强大的,甚至比谷歌的新产品还要强大 Trillium 芯片更好。
但NVIDIA已经发布的B200计算能力只有25%(每个芯片 1,250 TFLOPS)。这是由于 GPU 绝大多数区域用于可编程性,因此专注于可编程性 Transformer 芯片可以进行更多的计算。
例如,构建单个 FFP16/BF16/FP8 需要乘加电路 10,000 晶体管,这是所有矩阵数学的基石。NVIDIA H100 SXM 有 528 每张量核心,每张量核心,每张量核心4, x 8 × 16FMA 电路。
")
")
")
还没有评论,来说两句吧...