
整个行业的端到端切换,让汽车公司的智能驾驶竞争回到同一起跑线。
特斯拉基于端到端路线的特斯拉 FSD v12.5 版本在北美取得了惊人的效果。今年以来,国内玩家了解到智能驾驶升级的情况“武功秘籍”。(关于端到端的技术原理,虎嗅汽车团队在《特斯拉,与华为开战》一文中进行了详细分析)
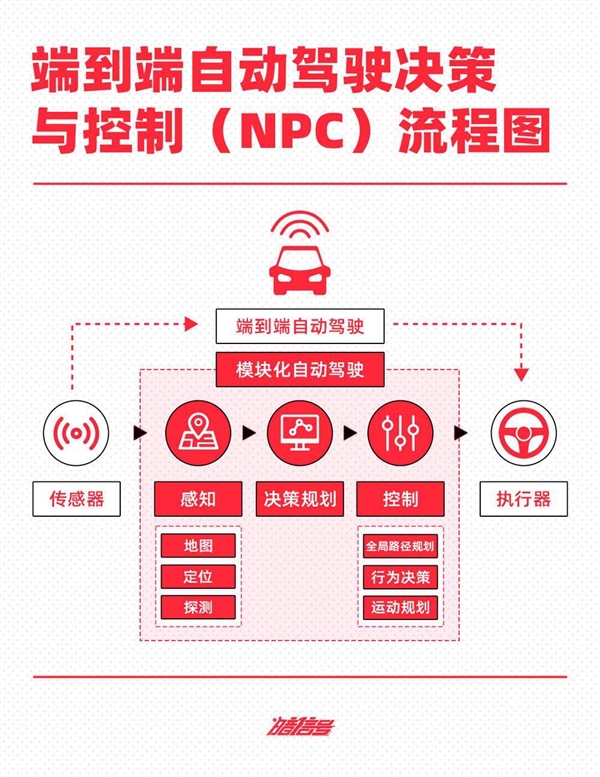
在模块化堆规则期间,代码bug修复能力越强,智能驾驶能力表现越好。同时,玩家可以通过开放城市和着陆速度来划分领域。但问题是,仅仅依靠传统的智能驾驶规则并不能从根本上解决现实世界的理解和推理问题,也不能解决许多复杂的场景和 Corner case。
因此,“上限不高”规则时代很快就被大模型和端到端的到来所取代,尤其是后者几乎“一日千里”迭代速度,也让不少车企纷纷将其规则转向端到端技术路径,其中包括蔚小理华等玩家。
端到端已成为智能驾驶行业下一代的共识方案,虽然没有人能清楚端到端是否是自动驾驶的终局方案,但目前还没有比端到端更好的智能驾驶技术方案。
基于此,本期暗信号旨在梳理场内头部玩家是如何进行的“端到端技术路线”布局,通过不同玩家的不同做法和落地进度,可以看到汽车企业智能驾驶能力的演变和下一个智能驾驶行业的竞争锚点。
理想:双系统协作,“世界模型”外挂
理想实际上是端到端路线的激进派。
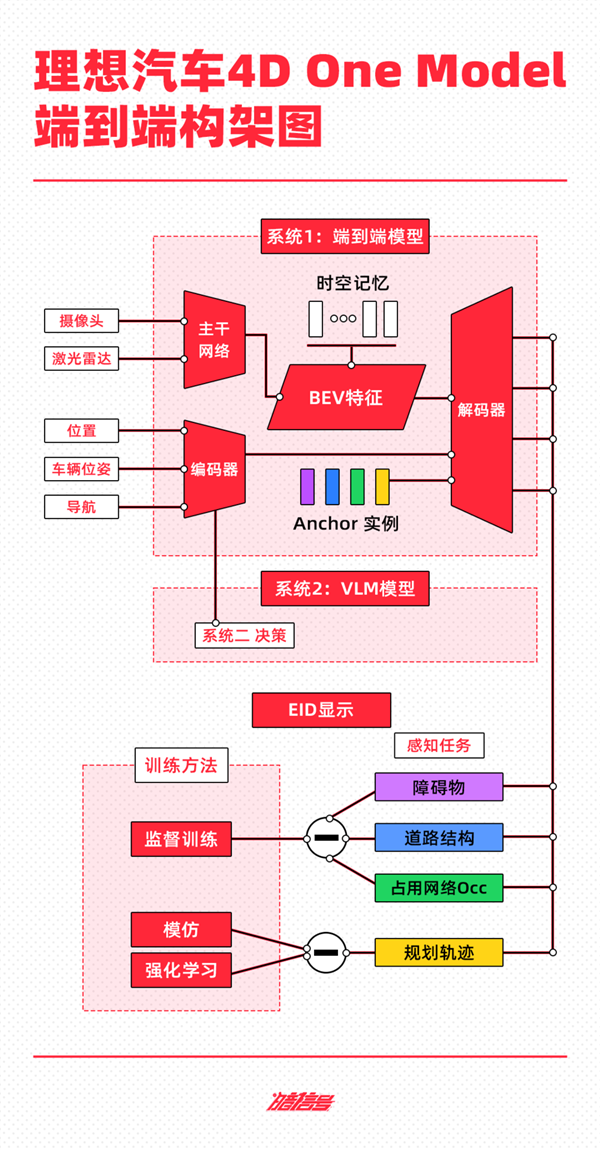
根据理想的汽车开放技术架构,端到端自动驾驶技术方案分为端到端模型、VLM 视觉语言模型、世界模型三部分。
理想汽车基于快慢系统理论,形成了自动驾驶算法架构的原型——
系统 1 由 One Model 实现端到端模型,通过接收传感器输入,并直接输出行驶轨迹来控制车辆;
系统 2 由 VLM 实现视觉语言模型,接收传感器输入后,通过逻辑思维,将决策信息输出到系统中 1。
由双系统组成的自动驾驶能力将在云中使用世界模型进行训练和验证。
端到端模型的输入主要由摄像头和激光雷达组成,多传感器特性通过 CNN 主干网络的提取与整合,投影至主干网络的提取与整合 BEV 空间,叠加车辆状态信息和导航信息,通过 Transformer 模型的编码,和 BEV 特征共同解码动态障碍物、道路结构和通用障碍物,规划出行轨迹。
目前,系统 1 现有的训练数据库 3 参数超过1亿,该模型在实际驾驶中具有较高的物理解能力、超视距导航能力、道路结构理解能力等。
系统 2 VLM视觉语言模型主要面向 5% 对于特殊交通场景,如分时限行、潮汐车道等负责交通规则的理解,相当于副驾驶在驾校教练时刻监督驾驶行为。目前,已有 22 亿参数。
VLM视觉语言模型的工作原理是用Tokenizer(分词器)编码Prompt(提示词)文本,用视觉信息编码前视相机的图像和导航地图信息,然后通过图文对齐模块进行模态对齐,最终统一自回归推理,输出对环境的理解、驾驶决策和驾驶轨迹,传递给系统1辅助控制车辆。
在实际应用场景中,如果系统二在行驶过程中发现地面路面非常坑洞,会给系统 1 发出降速提醒,并像ChatGPT一样告知驾驶员路面信息,最终输出驾驶建议,类似于ChatGPT“车辆将慢速行驶,以减少颠簸”。
除了这两个系统,理想的利用重建 生成世界模型为自动驾驶系统能力的学习和测试创造了一个虚拟环境,相当于通过生成真题库,使系统 1、2 测试虚拟世界,以验证和提高系统能力。
小鹏汽车:“三网融合”
")
")

还没有评论,来说两句吧...