
好羡慕!原来早在8月份,陶哲轩就已经用上了OpenAII o1。
还是现在大家都用不上的满血版本(眼泪不争气地从嘴角流出来)。
提前批大佬是怎么玩最新天花板的?
他向o1模型提出了一个模糊的数学问题,发现它可以成功地识别克莱姆定理。
而且答案是“完全令人满意”那种。

当然,陶哲轩也做了一些其他的测试,肉测下来的总体体验是:
比以前的模型好,多堆提示表现不错,但还是会犯很多错误,没有产生自己的想法。
陶哲轩是这样形容的:
这种感觉就像给一个平庸但有点能力的研究生提供建议。
然而,这比以前的模型有所改进,因为以前的模型能力更接近实际上不称职的研究生。
但是,如果你给以前的模型添加一些帮助,比如计算机代数包和证明辅助工具,你可以改进一两次,你可以实现进一步的迭代,改变,成为“有能力的研究生”。

陶哲轩对使用体验的神奇比喻在Hackernews等平台上引起了激烈的讨论。
有网友愤怒:什么是GPT!我承认LLMS对编写代码很有帮助,但事实上,有一些非常好的工具可以帮助解决这个问题,如代码片段、模板和代码生成器。
有人用陶哲轩的话回应他:
“任何足以编程为生的聪明人,智商都足以成为一名普通但能力较小的数学研究生。”

陶哲轩实测ChatGPTT vs o1
陶哲轩展示了自己的三轮测试。
第一轮,用去年3月测试ChatGPT的问题,要求大模型回答含糊的数学问题,只要从文献中找出合适的定理(克莱姆法则)就可以解决。
Say I have a positive measure whose closure(support) = some compact convex subset S. I convolve n times to get a measure on nS. Scale down by n, take log, divide by n, take the limit to get some rounded thing on S. Does it depend on the original measure?
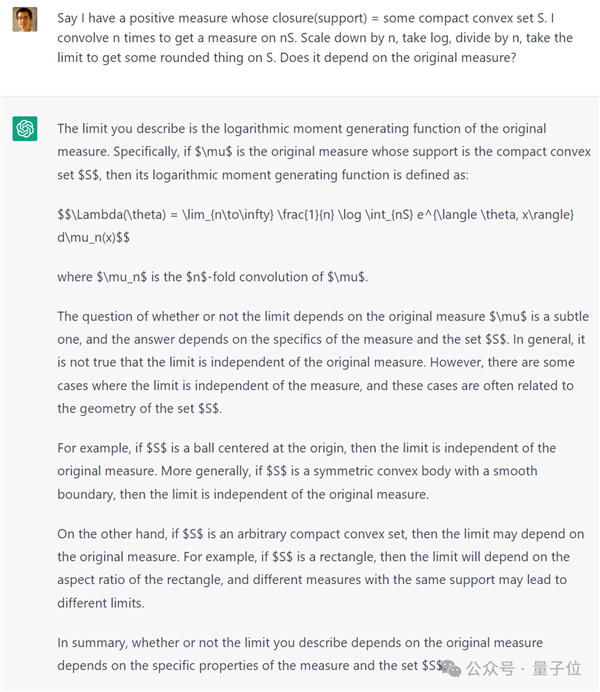
当时,ChatGPT回答得很好。在此期间,它还提到了一个高度相关的术语:数矩生成函数,甚至在给出的答案中讨论了一个具体的例子。但我们不能注意细节。都是幻觉,答案是错误的。
这一次,同样有模有样,但相比之下更有条理(更长的时间和大小标题的区分)。
最重要的是,o1成功地找到了克莱姆定理,并给出了一个完全令人满意的答案。

ps,看记录,早在8月份陶哲轩就用上了o1。
")
")
")
还没有评论,来说两句吧...